自动化测试概念及UI自动化测试¶
约 3047 个字 109 行代码 3 张图片 预计阅读时间 12 分钟
自动化测试的概念¶
自动化测试是指使用自动化工具执行事先编写好的测试用例,通过程序控制的方式来进行测试,并生成测试报告的过程。它能够模拟用户操作,验证软件功能是否符合预期。自动化测试的主要目的是用来进行回归测试
所谓回归测试,就是在软件修改后重新执行之前的测试用例,以确保新的代码变更没有破坏原有功能的测试方法
自动化的分类¶
自动化一般分为两种:
- 接口自动化:通过编写脚本或使用工具自动执行API接口测试,验证接口功能、性能和数据正确性的测试方法
- 界面(UI)自动化:通过编写脚本或使用工具模拟用户在图形界面上的操作(如点击、输入、滑动等),自动执行界面功能测试的方法。常见的界面自动化测试包含Web自动化测试、移动端自动化测试等
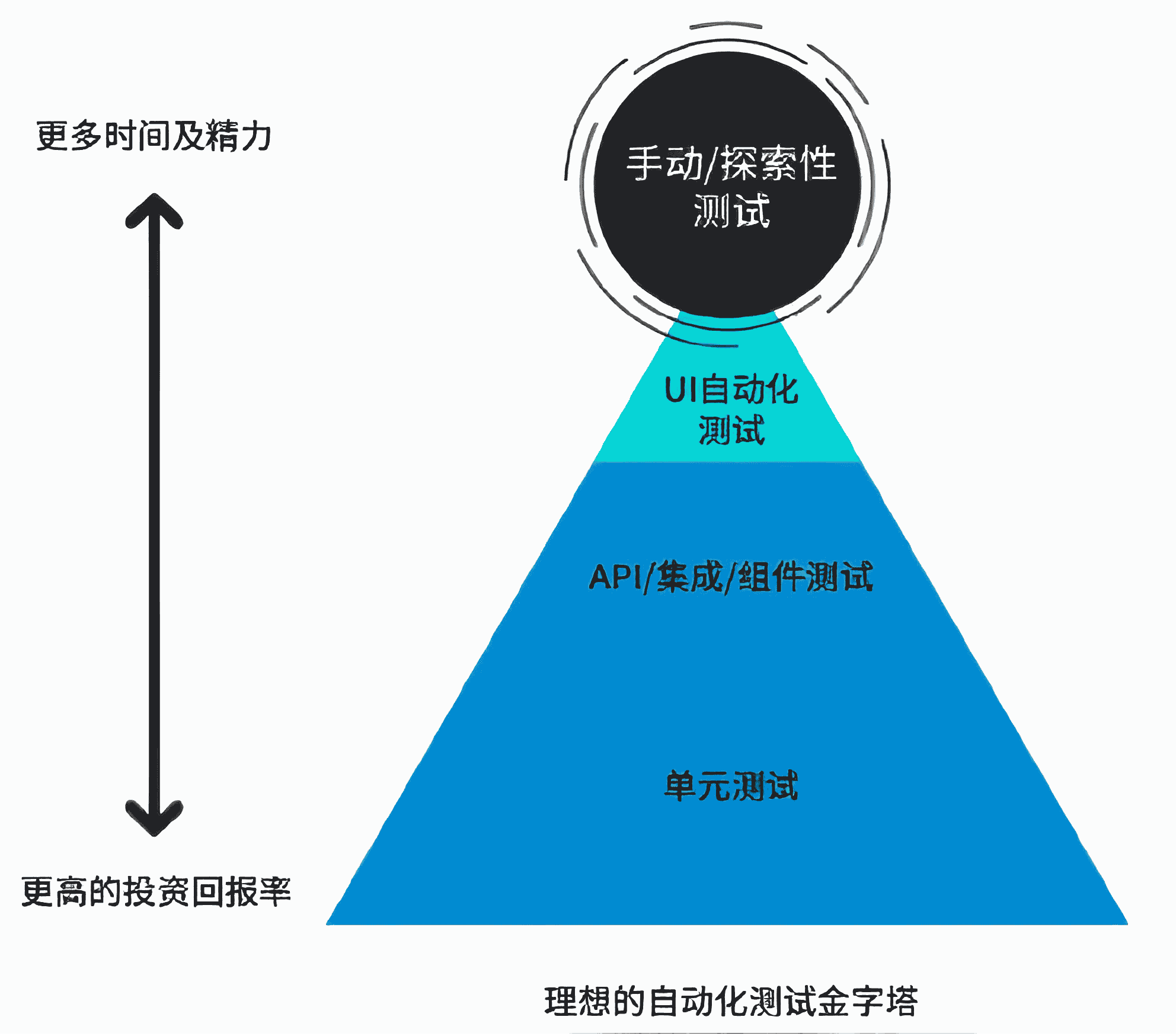
自动化测试金字塔¶
理想的自动化测试金字塔表达了自动化测试的理想情况,利用较少的时间和精力在单元测试上就能够发现更多有效的问题,如下图所示:
但是在实际开发中,常常表现为“冰激凌”的形状:
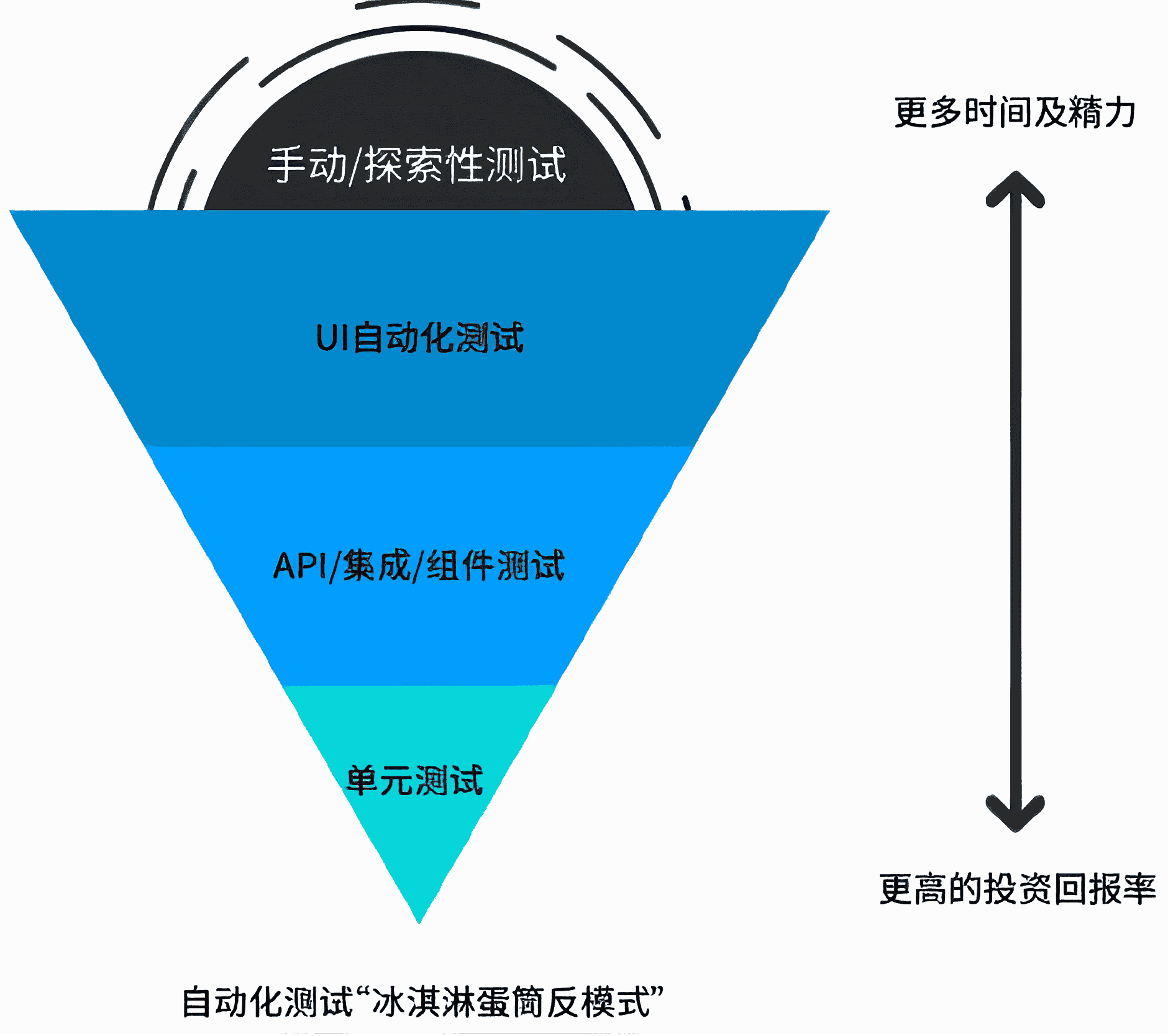
自动化需要大量的初始投资,找到“突破点”,与手动测试相比,我们开始看到它对长期成本产生的积极影响,也能够清楚,这两种测试活动都是完全兼容,产生短期和长期利益。需要注意,自动化测试并不能代替手动测试
Web自动化与Selenium介绍和基本使用¶
Web自动化是指通过编程方式控制浏览器自动执行网页操作(如点击、填表、导航等),实现Web应用功能测试和任务自动化的技术
实现Web自动化的方式有很多,比较有名的就是Selenium。Selenium是一个开源的Web自动化测试框架,支持多种编程语言和浏览器,能够模拟用户在浏览器中的各种操作来实现自动化测试
使用Selenium实现Web自动化一般需要执行下面的步骤:
- 下载指定浏览器的驱动
- 配置Selenium
- 使用Selenium模仿图形化界面中的操作
- 关闭浏览器(或者关闭当前驱动对应的标签页)
以Python为例,使用Selenium实现访问百度并搜索“柯懒不是柯南的博客”:
| Python | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
后续的介绍也将基于Python,其他的语言可以查看官方文档,基本使用类似
自动化测试相关函数¶
元素查找函数¶
元素查找函数分为两种:
- 查找唯一元素:
find_element,函数返回一个WebElement对象 - 查找多个元素:
find_elements,函数返回一个列表,列表中的元素都为WebElement对象
这两种函数使用方法一致,下面以find_element为例
在find_element中需要传递两个参数,第一个参数表示查找方式,第二个参数表示元素选择器。常见的查找方式是根据CSS选择器和XPath,对应的第一个参数分别为:
By.CSS_SELECTOR:使用CSS的选择器进行元素选择By.XPATH:使用XPath语法进行元素选择
XPath常见语法如下:
- 获取HTML页面所有的节点:
//* - 获取HTML页面指定的节点:
//[指定的节点] - 获取一个节点中的直接子节点:
/ - 获取一个节点的父节点:
.. - 实现节点的属性匹配:
[@...] - 使用指定索引的方式获取对应节点的内容(索引从1开始)
例如下面的代码:
| Python | |
|---|---|
1 2 | |
操作测试对象¶
常见的操作有:
- 点击元素
click() - 模拟按键输入
send_keys() - 清除文本内容
clear() - 获取文本信息
text - 获取元素属性
get_attribute()
这些操作需要的对象类型均为WebElement
例如:
| Python | |
|---|---|
1 2 3 4 5 6 | |
键盘按键¶
在Selenium中,键盘按键操作可以通过ActionChains对象实现,对应的键盘操作按键描述通过Keys类描述,对于非操作按键,可以参考此文档。具体使用方式可以参考官方文档
常见的操作有:
- 按键按下(不释放):
key_down - 按键释放:
key_up - 按键按下立即释放:
send_keys
例如下面的代码:
| Python | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 | |
获取页面的标题和URL¶
- 获取页面标题:
title - 获取页面URL:
current_url
例如:
| Python | |
|---|---|
1 2 3 4 5 6 7 | |
窗口与切换¶
现在有这样一个场景,需要获取到页面跳转前后的标题和URL
以百度为例,如果是原地跳转,那么可以直接获取:
| Python | |
|---|---|
1 2 3 4 5 6 7 | |
但是如果是异地跳转,那么上面的代码获取到的两次标题和URL是相同的。出现这个问题的原因就在于虽然网页的确发生了跳转,但是驱动程序还停留在上一个页面,例如点击百度首页左上角的“图片”链接后:
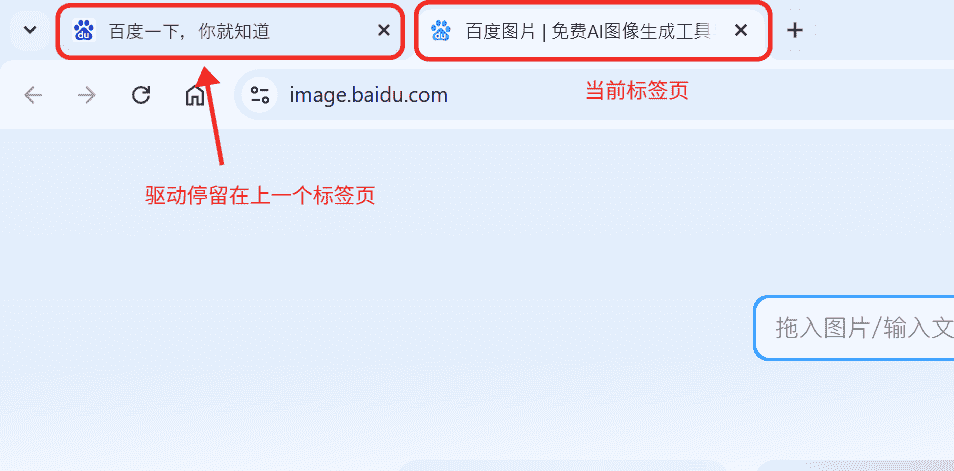
此时两次获取页面标题和URL均为百度一下,你就知道,页面网址:https://www.baidu.com/
要解决这个问题就需要知道如何让驱动切换页面。在Selenium中,要实现这个效果,可以通过下面的步骤在两个标签中切换到另外一个标签:
- 获取到当前窗口句柄:使用
current_window_handle - 获取到所有窗口句柄列表:使用
window_handles - 遍历所有窗口句柄列表找到非当前窗口句柄
- 切换窗口:使用
switch_to中的window(窗口句柄)
例如下面的代码:
| Python | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
窗口操作¶
常见的窗口操作有以下几种:
- 最小化窗口:使用
minimize_window() - 最大化窗口:使用
maximize_window() - 手动设置窗口大小:使用
set_window_size(width, height)。需要传递两个参数,分别表示宽度和高度 - 全屏窗口:使用
fullscreen_window()
例如:
| Python | |
|---|---|
1 2 3 4 5 6 7 8 | |
屏幕截图¶
屏幕截图可以使用save_screenshot(filename)函数,参数传递文件名(可以指定路径)。但是直接固定文件名会导致新的图片覆盖旧的图片,所以在截图时一般会考虑带上截图的时间,这里可以使用Python的内置库datetime中的函数now()来获取到当前系统时间,但是这个时间不能直接作为文件名,所以还需要考虑将时间进行格式化,可以调用strftime()函数进行格式化。例如:
| Python | |
|---|---|
1 2 3 4 | |
如果想做到「不存在screenshots文件夹就创建,否则不创建」的操作,可以使用Python的os库进行文件操作:
| Python | |
|---|---|
1 2 | |
关闭标签页¶
关闭标签页可以使用close()函数:
| Python | |
|---|---|
1 | |
close()函数与quit()函数的不同点在于close()并不会退出浏览器软件,只是关闭当前的标签页,但是quit()会直接退出浏览器。需要注意的是,因为驱动和标签页是绑定的,所以一旦调用了close(),那么之后想在使用驱动需要重新获取指定页面
弹窗操作¶
前面使用find_element都是获取到网页内部的元素,但是对于弹窗来说其不属于网页内部的内容,也就无法通过find_element来获取。对于浏览器弹窗一般分为三种:
- 警告弹窗(通过
alert实现) - 确认弹窗(通过
confirm实现) - 提示弹窗(通过
prompt实现)
处理弹窗有一套固定的逻辑:
- 切换到弹窗:通过
switch_to的alert实现 - 接受弹窗或者取消弹窗:分别通过
accept()和dismiss()实现。其中,对于警告弹窗来说,accept()和dismiss()效果一致
特殊地,提示弹窗中的文本框可以通过send_keys()实现内容输入
例如:
| Python | |
|---|---|
1 2 | |
导航操作¶
浏览器导航分为下面几种:
- 前进:通过
forward()实现 - 后退:通过
back()实现 - 刷新:通过
refresh()实现
例如:
| Python | |
|---|---|
1 2 3 4 5 6 | |
文件上传¶
文件上传与内容输入非常类似,只是send_keys()为待上传的文件的绝对路径,例如:
| Python | |
|---|---|
1 | |
等待方式¶
除了使用time库中的sleep(seconds)函数以外,Selenium还提供了两种等待方式:
- 隐式等待:也称为智能等待。驱动启动时通过调用
implicitly_wait(seconds)函数设置等待时间,在查找元素时会消耗设置的等待时间,一旦某一个查找元素函数执行超时(一般是没有查找到元素)就报错,否则不报错 - 显式等待:在执行查找指定元素之前先通过创建
WebDriverWait对象设置超时时间,再由WebDriverWait对象根据指定条件通过until()进行等待,如果超时时间之内满足指定的条件,则不进行如何操作;如果没有满足指定条件或者超时,则报错
until()接口中可以传递expected_conditions,其是Selenium WebDriver中用于显式等待的一组预定义条件集合。以下是所有方法及其作用的介绍:
| 方法名 | 作用 |
|---|---|
title_is(title) | 判断当前页面的标题是否完全等于给定的字符串 |
title_contains(title) | 判断当前页面的标题是否包含给定的字符串 |
presence_of_element_located(locator) | 检查元素是否存在于DOM中(不一定可见) |
visibility_of_element_located(locator) | 检查元素是否存在于DOM中并且可见 |
visibility_of(element) | 检查给定的元素是否可见 |
presence_of_all_elements_located(locator) | 检查定位器定位的所有元素是否都存在于DOM中 |
text_to_be_present_in_element(locator, text_) | 检查给定的文本是否出现在指定元素中 |
text_to_be_present_in_element_value(locator, text_) | 检查给定的文本是否出现在指定元素的value属性中 |
frame_to_be_available_and_switch_to_it(locator) | 检查frame是否可用并切换到该frame |
invisibility_of_element_located(locator) | 检查元素是否不可见或不存在于DOM中 |
element_to_be_clickable(locator) | 检查元素是否可见且可点击 |
element_to_be_selected(element) | 检查元素是否被选中 |
element_located_to_be_selected(locator) | 检查定位的元素是否被选中 |
element_selection_state_to_be(element, is_selected) | 检查元素的选中状态是否符合预期 |
element_located_selection_state_to_be(locator, is_selected) | 检查定位元素的选中状态是否符合预期 |
number_of_windows_to_be(num_windows) | 检查当前窗口数量是否达到预期数量 |
new_window_is_opened(current_handles) | 检查是否有新窗口打开 |
url_to_be(url) | 检查当前URL是否完全等于给定URL |
url_contains(url) | 检查当前URL是否包含给定字符串 |
url_matches(pattern) | 检查当前URL是否匹配给定的正则表达式模式 |
alert_is_present() | 检查是否出现alert弹窗 |
例如:
| Python | |
|---|---|
1 2 3 4 5 6 7 8 | |
until中也可以使用Lambda表达式,例如:
| Python | |
|---|---|
1 2 3 4 5 6 7 8 | |
需要注意的是,隐式等待设置的是全局等待时间,也就是说,隐式等待的生命周期随驱动的结束(调用quit())而结束,所以不建议隐式等待和显式等待一起使用,因为无法预估出总共需要等待的时间
启动参数¶
设置启动参数可以通过webdriver.ChromeOptions()的add_argument()进行设置,例如设置无头模式:
| Python | |
|---|---|
1 2 3 4 | |
加载策略¶
设置加载策略webdriver.ChromeOptions()的page_load_strategy参数进行设置,有三种取值:
| 加载策略 | 描述 | 特点 |
|---|---|---|
normal | 默认加载策略,等待页面所有资源加载完成 | 等待HTML文档、CSS、JavaScript、图片等所有资源完全加载后才继续执行 |
eager | 等待DOMContentLoaded事件触发 | 只等待HTML文档完全加载和解析完成,不等待样式表、图片和子框架等资源加载 |
none | 只等待初始HTML文档加载完成 | 最快速的加载方式,只等待最初的HTML文档加载完成就继续执行 |
例如:
| Python | |
|---|---|
1 | |