Linux下的Makefile与进度条程序¶
约 3882 个字 273 行代码 18 张图片 预计阅读时间 16 分钟
Makefile与make¶
Makefile与make介绍¶
在Linux中,Makefile是一个文件,make是一个指令,当使用make指令时,该指令会在当前目录下找Makefile文件从而执行内部的内容
创建第一个Makefile并使用make¶
首先,在当前目录下创建一个Makefile文件(也可以写成makefile),例如:

接下来在同级目录下创建一个code.c文件
使用vim编辑器输入下面的内容:
| C | |
|---|---|
1 2 3 4 5 6 7 | |
保存code.c文件后退出当前vim,使用vim打开Makefile文件,输入下面的内容:
| Makefile | |
|---|---|
1 2 3 4 5 | |
Note
需要注意,gcc -o code code.c和rm -rf code前方是一个Tab键的大小,而不是4个或者8个空格
保存Makefile文件后退出当前vim,在当前目录下输入make指令即可在当前目录下创建code.c对应的可执行文件(具有可执行权限并且文件本身可执行)code,例如下图:
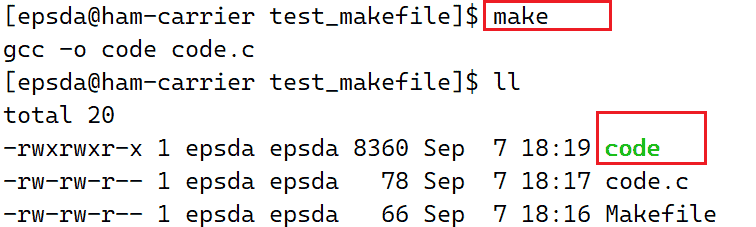
通过常规方式运行该可执行文件./code即可看到打印输出的内容:

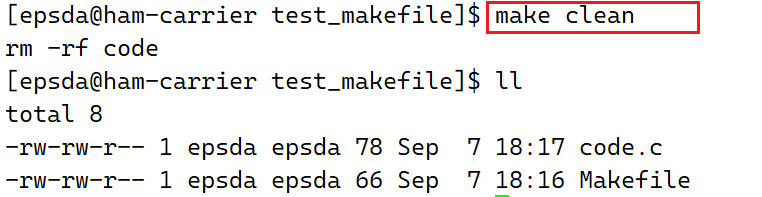
接着使用make clean指令清理刚才生成的可执行文件code:
Makefile文件基本格式介绍¶
以前面例子中的Makefile为例:
| Makefile | |
|---|---|
1 2 3 4 5 | |
- 第一行中的
code:code.c代表依赖关系,code表示目标文件,code.c表示依赖文件列表中的文件,第二行的gcc -o code code.c代表依赖方法(指令) - 第三行中的
.PHONY表示生成一个伪目标,clean表示伪目标的名字(可以类比变量名) - 第四行及第五行与第一行及第二行含义一致,表示依赖关系和依赖方法,而因为
clean没有需要依赖的文件,所以clean:后没有任何依赖文件列表文件
依赖关系:表示两个文件之间构成的一定关系,比如父子关系
依赖方法:通过依赖方法可以执行的对应的指令
依赖文件列表:code.c所处的位置即为依赖文件列表,为了生成目标文件code而需要的文件称为依赖文件,依赖文件列表可以含有不止一个文件
Note
注意:理论上来说,依赖文件列表中的code.c在当前情况下可以不写,但是如果不写,在第一次执行make指令后,不论之后code.c是否修改,再执行make指令都无法执行对应的依赖方法,因为code文件已经存在,所以为了保证可以修改,需要加上code.c
从上面的运行结果可以看出,每一次执行make时都会在控制台回显出对应的依赖方法,如果将编译指令改为echo "测试",则效果如下:

可以看到先回显了对应的依赖方法,再执行依赖方法,如果不希望出现这种情况,可以在执行的指令前加上@使指令不再回显,所以上面的Makefile可以修改为:
| Makefile | |
|---|---|
1 2 | |
运行结果如下:

所以原始的Makefile可以修改为:
| Makefile | |
|---|---|
1 2 3 4 5 6 7 8 9 | |
Note
一个依赖集中可以有多个依赖方法
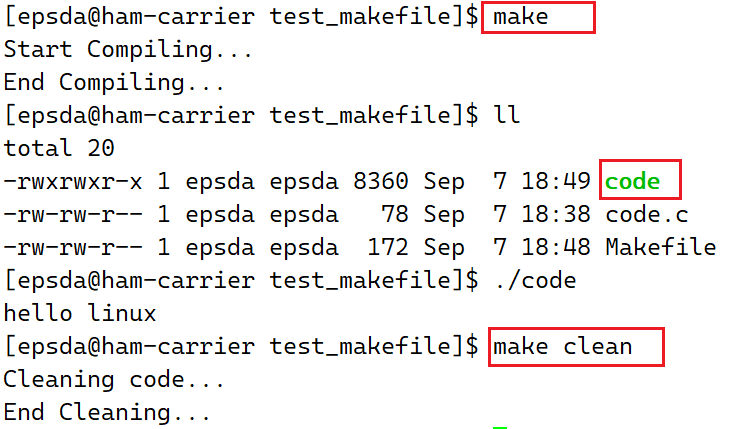
此时正常运行结果如下:
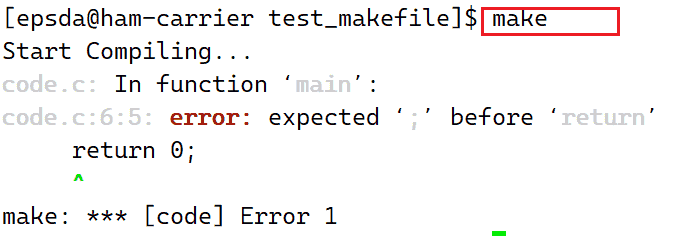
如果代码出现错误,则gcc会中断编译,所以此时运行结果如下:
使用.PHONY可以生成一个指定名字的伪目标,伪目标的作用是:清除依赖方法执行时进行的文件时间对比,下面是具体介绍:
首先,在Linux中可以使用stat+文件名查看文件当前的属性,对于code.c有:
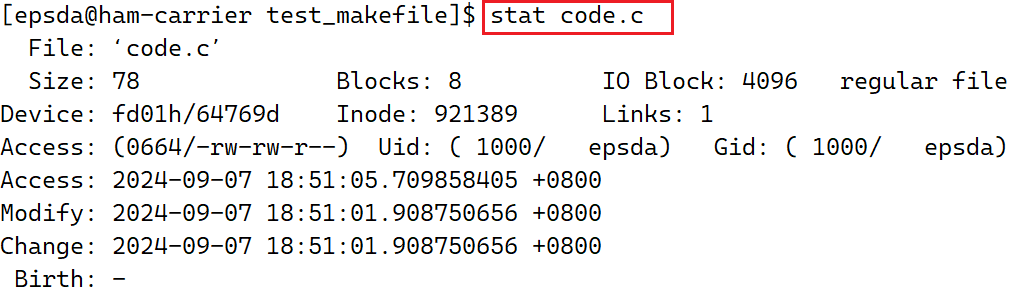
执行结果中,主要关注三个部分:Access、Modify和Change,这三个部分分别表示文件最近一次的访问时间、文件内容被修改的时间和文件属性被修改的时间
Access时间:一般不是特别精确,因为如果一个文件访问一次就需要更新一次访问时间,那么对于多个文件来说,这种操作的消耗对于CPU来说是很大的Modify时间:Modify时间只表示文件内容被修改的时间,如果文件属性时间修改,则不影响Modify时间,但是需要注意,Modify时间一旦改变一般伴随着Change时间改变,因为修改文件内容有时会影响到文件的相关属性(例如文件大小等)Change时间:Change时间只表示文件属性被修改的时间,修改文件属性时间不会影响Modify时间
接着,观察对于没有添加伪目标的Makefile第一部分依赖集,如果code文件已经存在,再一次进行make的效果:
| Makefile | |
|---|---|
1 2 3 4 | |

如果此时对code.c文件进行修改,那么执行结果会有所不同:

那么指令是如何知道文件是否被修改呢?就是通过前面提到的Modify时间和Change时间,过程如下图所示:
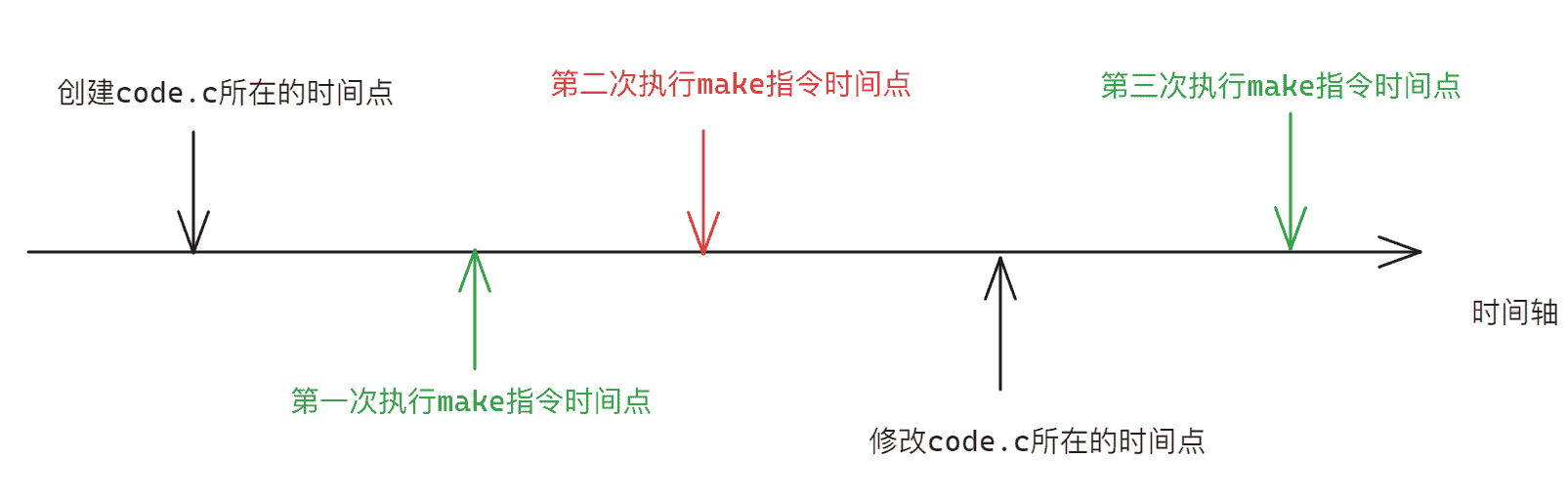
因为code.c创建的时间早于code.c编译的时间,所以开始时不存在code文件,所以第一次执行make指令时正常执行。
当code.c文件未修改时,第二次执行make指令会发现code.c的Modify时间和Change时间依旧在make之前,因为第一次已经满足了code.c的两个时间在code文件的两个时间之前,所以gcc就不会再进行一次编译。
当修改code.c文件后,code.c的Modify时间和Change时间改变,导致code.c的两个时间在code文件的两个时间之后,此时gcc就可以正常执行,从而make指令不受影响
而如果再Makefile中为这一部分添加一个伪目标,则可以清除指令中文件时间的对比过程:
| Makefile | |
|---|---|
1 2 3 4 5 | |
此时无论执行多少次make指令,都不会出现make指令中gcc因为文件时间对比而导致执行结果不同:

Note
make指令虽然结果完全相同,但是不代表依赖方法没有执行,即文件确实每一次都重新编译
执行完编译部分的make指令,想要执行删除code文件对应的make指令需要在make后加上clean,这个clean代表伪目标名,之所以前面直接使用make就可以执行编译指令,是因为make指令在读取Makefile文件时是从上至下顺序查找,而直接使用make,就会执行第一个依赖集对应的依赖方法,执行完毕后就不会再继续往下读;而对于删除code文件的指令来说,其所在位置时Makefile中的第二个依赖集,所以需要告诉make指令找哪一部分
所以,此处可以看出.PHONY的第二个作用就是声明一个伪目标,通过该伪目标帮助make指令快速定位需要执行的依赖集
如果细心可以发现,对于clean依赖集来说,不论是否有.PHONY都可以无限制执行rm -rf依赖方法,所以可以推断出rm -rf指令本身不会考虑文件的时间属性,但是为什么此处还需要加.PHONY?一方面是为了声明伪目标,另一方面是为了当前依赖集中的其他指令会有时间对比
Makefile依赖方法执行过程¶
前面学习到,当执行gcc -o code code.c实际上是分成了四步,即:
code.c文件编译生成code.i文件code.i文件编译生成code.s文件code.s文件编译生成code.o文件code.o文件编译生成code可执行文件
将对应的指令写入Makefile中,代码如下:
| Makefile | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 | |
根据make从上至下的运行顺序,首先执行gcc -o code code.o,但是,因为code.o不存在,并且code.o文件依赖于code.s文件,所以继续执行code.o:code.s对应的依赖方法,以此类推直到最后一条依赖方法gcc -E code.c -o code.i执行向上返回执行前面未执行的依赖方法。整个过程可以理解为在一个栈中操作:
Note
假设此处执行的依赖方法同样进栈
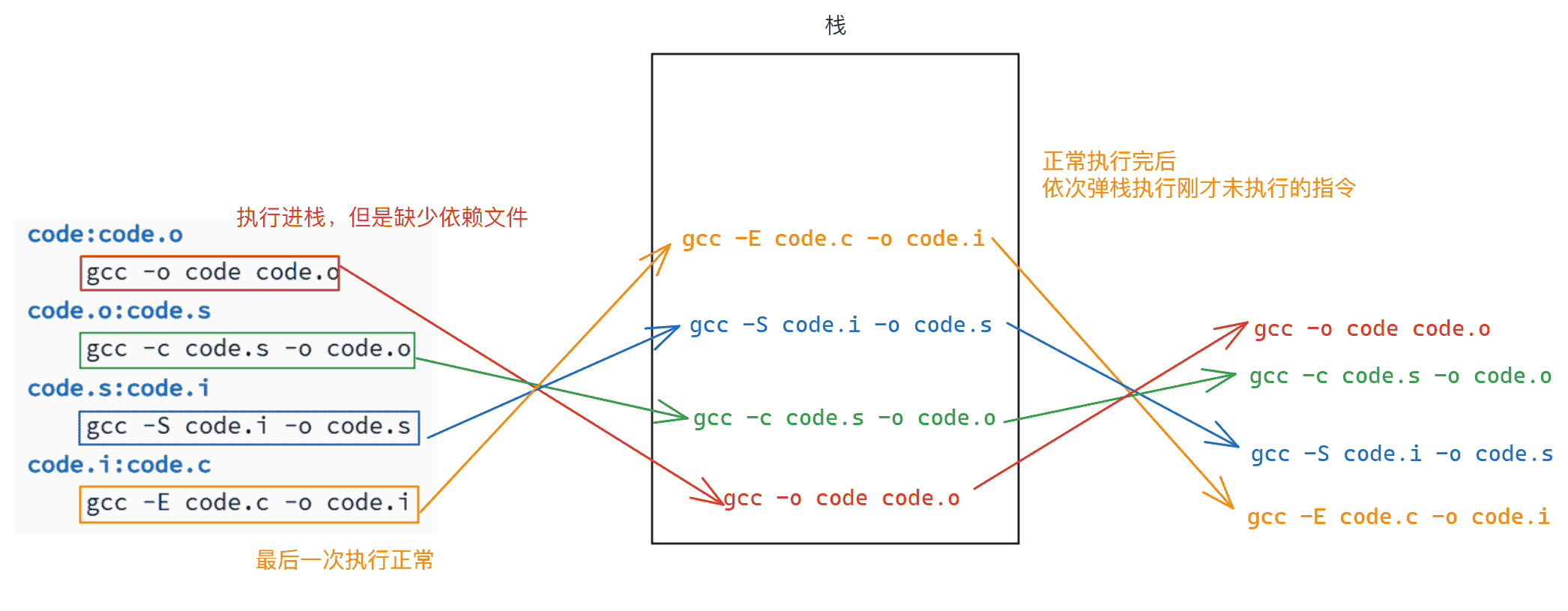
所以执行的结果如下图所示:

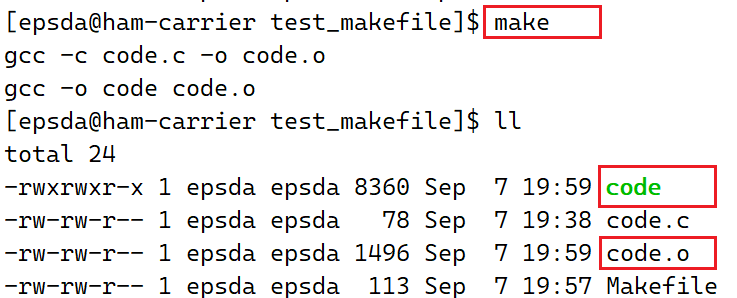
实际上,在真正开发中,只需要用到两个部分,如下:
| Makefile | |
|---|---|
1 2 3 4 | |
此时运行结果如下:
Makefile通用写法¶
在前面的Makefile中,每一个依赖方法都需要在前面的依赖关系部分的文件重新写一遍,为了简化过程,可以使用下面的写法:
| Makefile | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 | |
上面的代码中,首先创建了两个变量分别代表生成的目标文件code以及第一个依赖集中的依赖文件列表中的文件,在依赖方法中使用了两个自动变量(一般建议大写),分别是$@和$<
在Makefile中,$@表示生成的目标文件,$<表示从依赖文件列表中取出一个文件,对应的还有$^表示依赖文件列表中的所有文件。如果想表示当前目录下的所有相同后缀的文件,可以使用%通配符,例如上面的Makefile中使用%.c代表匹配当前目录下所有后缀为.c的文件
而对于gcc来说,在Makefile中可以使用内置变量CC(表示C编译器的名字)代替
如果涉及到多个文件编译,则在SRC和%.c处使用空格分隔每一个文件
但是,上面的Makefile并没有完全实现通用性,主要的问题还是「每一次创建新的文件就要修改Makefile文件」,如果文件比较多一个一个写也不利于添加,所以考虑结合变量以及指令让Makefile批量添加文件
在Makefile中,可以使用shell命令,例如可以使用ls *.c表示展示当前目录下的.c后缀文件,如果结合变量,就是SRC=$(shell ls *.c),这个做法也可以使用Makefile的内置函数wildcard实现,所以也可以写成SRC=$(wildcard *.c)。在这两个变量创建语法中,$()表示调用,也可以写成${},二者没有区别
所以上面的Makefile可以修改为:
| Makefile | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 | |
如果想对文件名中的指定内容进行简单的替换,也可以结合变量和$(),语法为:变量名=$(原始内容=替换内容),例如将当前目录下所有的.c文件替换为.o文件,就可以写成:
| Makefile | |
|---|---|
1 2 3 | |
此处用到的$(SRC:.c=.o)表示引用或计算变量SRC的值,并将结果中的.c替换为.o
Note
上面的替换规则不会改变原始文件中的内容,也就是说,在上面的例子中,.c文件的内容不会真正被替换为使用编译器生成的.o的文件内容
至此,一个基本的Makefile文件编写语法就这么多,如果需要更详细了解Makefile文件,请移步至此->Makefile教程
进度条程序¶
实现效果¶

前置知识¶
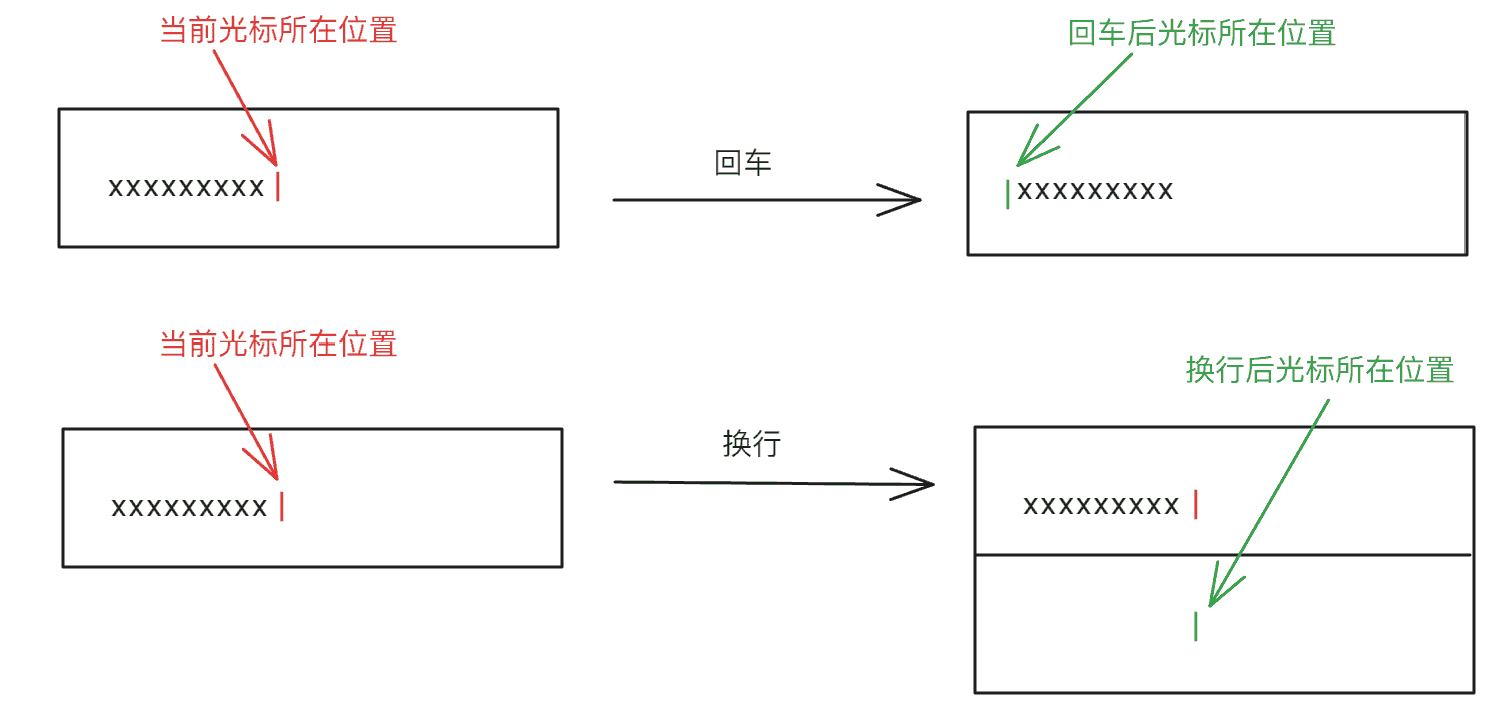
回车(\r)与换行(\n)¶
在C语言或者其他高级语言中,换行(\n)表示回到下一行的开始处,实际上换行的效果并不如此
回车(\r):回到当前光标所在行的开始
换行(\n):前往光标所在行的下一行,但是光标是平行向下移动
输出缓冲区¶
观察下面程序运行的结果:
| C | |
|---|---|
1 2 3 4 5 6 7 8 9 | |
如果在Linux终端运行该程序,可以看到程序先打印了hello linux,然后等待了2秒才显示prompt提示
Note
这里的sleep函数不是Windows下的Sleep函数,但是效果基本一致
将上面的程序修改为下面的程序,再观察效果:
| C | |
|---|---|
1 2 3 4 5 6 7 8 9 | |
可以看到程序先等待了2秒,然后才打印hello linux
C语言程序默认从上往下顺序执行代码,所以不可能是先执行了sleep(2)才执行printf("hello linux");,出现这种现象的原因就是因为缓冲区的存在,程序在输出时并不会直接将内容输出到显示器上,而是先输出到输出缓冲区,再通过刷新/结束缓冲区将内容打印到屏幕上,而之所以在有\n时会显示再等待就是因为\n刷新了缓冲区,导致内容打印到了屏幕上
如果使用将\n替换为\r则同样会先等待再打印,因为\r也不具备刷新缓冲区的效果,如果在当前情况下想刷新缓冲区但又不想使用\n,则可以使用fflush()函数,传递参数为标准输出stdout,代码如下:
| C | |
|---|---|
1 2 3 4 5 6 7 8 9 10 | |
实现进度条¶
基础版本¶
思路:首先创建3个文件,分别是测试文件main.c、头文件process.h和实现文件process.c。对于进度条,实际上就是先打印原数组内容,再填充数组然后刷新缓冲区,对于百分比,只需要使用循环变量控制即可,对于最右侧闪烁的符号,实际上就是四个动画帧符号,每一次循环加载一个动画帧即可,但是为了循环加载,需要使下标在指定范围内循环,可以考虑循环队列(数组版)下标轮回的思路,所以基本代码如下:
| C | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | |
对应的Makefile如下:
| Makefile | |
|---|---|
1 2 3 4 5 6 7 8 9 | |
改进版本¶
前面的进度条只是根据100进行依次填充,并没有达到进度条的实用性「根据下载进度更新进度条」,所以可以通过下面的思路对上面的代码进行优化:
首先,定义一个函数download,该函数用于定义下载任务
假设需要下载的文件FILE大小为2048MB,定义一个带宽BASE为1MB,为了模拟出网络波动,可以使用(rand()%BASE+1)/10计算出增量,用增量乘以BASE计算出下载速度speed,但是需要注意,因为rand()%BASE+1计算出的值为整数,整数除以10依旧为整数,所以此时值只会为0,为了解决这个问题可以将rand()%BASE+1强转为double再除法运算
定义两个变量分别为current和total,分别代表当前下载量和总下载量,因为需要根据百分比显示更新进度条,所以这两个变量需要使用double类型定义,百分比计算公式:current / total * 100
模拟下载效果可以使用一个循环,循环体内使current不断根据速speed进行更新,但是这里可能最后计算出的current不一定刚好等于double,为了防止出现进度条计算出的百分比大于1,可以使用一个矫正「当current大于等于total时,就将total赋值给current」,当current大于或等于total时结束循环
前面的进度条只是单纯根据100进行填充,所以需要使用循环。但是此处更新进度条不可以再使用循环,否则会出现「更新一次current,进度条就跑满一次的问题」,正确的思路是「更新一次current,进度条更新一次」
进度条的设计分成两部分:
- 进度条填充图案及动画
- 进度条加载图案及动画(这个不是必须的,但是如果出现进度条卡住等问题,该图案可以用于辨别是系统卡住还是下载卡住)
对于「进度条填充图案及动画」来说,主要思路是根据下载百分比更新进度条,所以可以使用变量rate存储百分比,根据该百分比进行数组图案循环填充,但是需要注意,因为百分比为double类型,存在精度损失问题,所以在作为循环结束条件比较运算符的右操作数时需要强转为int,同样的思路打印进度条填充图案及显示动画即可
对于「进度条加载图案及动画」来说,这里使用.作为加载图案,重点考虑如何实现依次打印「.」「..」「...」「....」「.....」「......」并循环往复。每一次调用进度条可以考虑更新一次符号,和填充图案类似,但是需要每一次更新指定数量的.,可以定义一个静态变量,每一次调用更新一次,但是必须确保不超过设计的数量,这里假设数量PNUM为6,即一共6个.,在循环中根据PNUM进行循环,如果i小于num,就打印.(通过num控制.的个数),否则打印空格进行占位,使用打印进度条的思路打印加载动画即可
最后,可以考虑使用一个count变量降低加载动画的速度
示例代码:
| C | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 | |
最终版本¶
为了使下载函数更加具有通用性,可以使用函数指针,将进度条的函数声明使用typedef声明为pro,使用该函数指针在下载函数形参位置声明一个变量,在下载函数内部使用形参调用对应形参指向的进度条函数,之后如果有多个进度条代码,只要进度条代码的函数声明于形参函数指针执行的函数类型相同,就可以更换为其他的进度条代码执行
| C | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 | |