Java双列集合¶
约 3865 个字 320 行代码 4 张图片 预计阅读时间 17 分钟
Java双列集合体系介绍¶
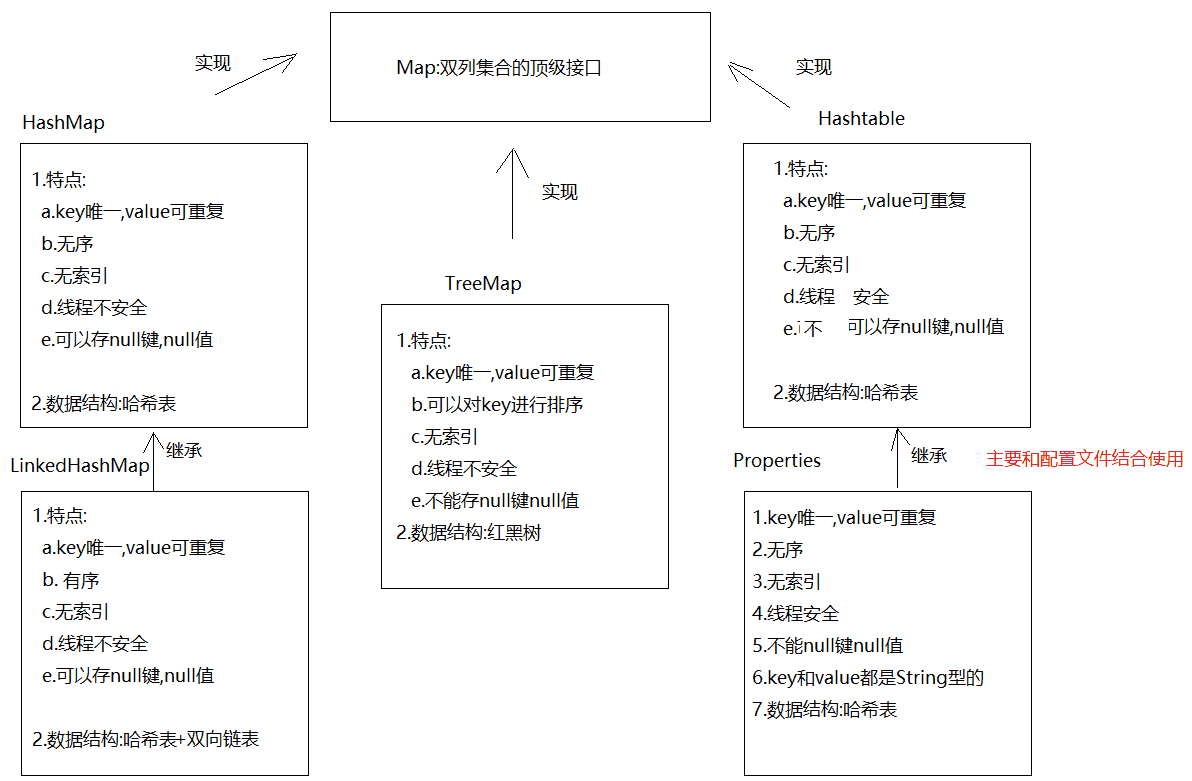
在Java中,双列集合的顶级接口是Map接口,该类没有继承自Collection,该类中存储的是<K,V>结构的键值对,并且K一定是唯一的,不能重复
在Map接口中有下面的分类:
HashMap类LinkedHashMap类TreeMap类HashTable类Properties类
其体系及特点如下图所示:
Map.Entry<K, V>接口介绍¶
Map.Entry<K, V>是Map内部实现的用来存放<key, value>键值对映射关系的内部类,该内部类中主要提供了<key, value>的获取、value的设置以及key的比较方式,其下有下面几个常用的方法:
K getKey():返回entry的键keyV getValue():返回entry的值valueV setValue(V value):将指定键值对中的value替换为参数的value
Note
需要注意,Map.Entry<K,V>并没有提供设置key的方法
TreeMap类¶
介绍¶
TreeMap类是Map接口的实现类,其特点如下:
- 默认会对插入的数据进行排序,所以存储的类型必须实现
Comparable接口,或者提供实现了Comparator的比较器 - 没有索引的方式操作元素
key唯一,value不唯一- 不可以存
null值 - 相同元素不重复出现
- 线程不安全
底层数据结构为红黑树
构造方法¶
常用构造方法:
- 无参构造方法:
TreeMap(),默认按照ASCII码对元素进行比较 - 使用传递比较器作为参数的有参构造方法:
TreeMap(Comparator<? super E> comparator)
常用方法¶
V get(Object key):返回指定键key的值valueV getOrDefault(Object key, V defaultValue):返回指定键key的值value,如果没有该键key,则返回默认值defaultValueV put(K key, V value):插入键值对,返回被参数value覆盖的valueV remove(Object key):根据key值移除TreeMap中指定的元素,返回被删除的键值对对应的valueSet<K> keySet():返回TreeMap中所有key值的集合(key不可以重复)Collection<V> values():返回TreeMap中所有value值的集合(value可以重复)Set<Map.Entry<K, V>> entrySet():返回TreeMap中所有键值对的集合boolean containsKey(Object key):判断TreeMap中是否还有指定key元素boolean containsValue(Object value):判断TreeMap中是否还有指定value元素int size():返回TreeMap中键值对的数量
基本使用如下:
| Java | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
遍历集合¶
HashMap遍历方式有以下两种:
- 通过
key值获取到对应的value,通过Set<K> keySet()方法将获取到的key存入到Set中,再使用Set集合的迭代器获取对应的value - 通过
Set<Map.Entry<K,V>> entrySet()获取到HashMap中的键值对存入到Set中,再通过Map的内部静态接口Map.Entry中的getKey方法和getValue方法分别获取到Map中对应的键值对
例如下面的代码:
| Java | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
HashMap类¶
介绍¶
HashMap类是Map接口的实现类,其特点如下:
key唯一但value不唯一- 插入顺序与存储顺序不一定相同
- 没有索引方式操作元素的方法
- 线程不安全
- 可以存
null值
对应的数据结构为哈希表
Note
需要注意,如果出现key重复会保留最后一个键值对的value,即「发生value覆盖」
构造方法¶
常用构造方法:
- 无参构造方法:
HashMap(),默认初始容量为16,负载因子为0.75 - 传递初始容量的有参构造方法:
HashMap(int initialCapacity),默认负载因子为0.75 - 传递初始容量和负载因子的有参构造方法:
HashMap(int initialCapacity, float loadFactor)
常用方法¶
V get(Object key):根据key值获取对应的valueV getOrDefault(Object key, V defaultValue):根据key值获取对应的value,如果没有该键key,则返回默认值defaultValueV put(K key, V value):向HashMap中插入元素,返回被参数value覆盖的valueV remove(Object key):根据key值移除HashMap中指定的元素,返回被删除的键值对对应的valueSet<K> keySet():返回HashMap中所有key值的集合(key不可以重复)Collection<V> values():获取HashMap中所有的value,将其值存储到单列集合中(value可以重复)Set<Map.Entry<K, V>> entrySet():返回HashMap中所有键值对的集合boolean containsKey(Object key):判断HashMap中是否还有指定key元素boolean containsValue(Object value):判断HashMap中是否还有指定value元素int size():返回HashMap中键值对的数量
使用与TreeMap类似,此处不再演示
遍历集合¶
HashMap遍历方式有以下两种:
- 通过
key值获取到对应的value,通过Set<K> keySet()方法将获取到的key存入到Set中,再使用Set集合的迭代器获取对应的value - 通过
Set<Map.Entry<K,V>> entrySet()获取到HashMap中的键值对存入到Set中,再通过Map的内部静态接口Map.Entry中的getKey方法和getValue方法分别获取到Map中对应的键值对
例如下面的代码:
| Java | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
LinkedHashMap类¶
介绍¶
key唯一但value不唯一- 插入顺序与存储顺序相同
- 没有索引方式操作元素的方法
- 线程不安全
- 可以存
null值
对应的数据结构为哈希表+双向链表
常用方法¶
LinkedHashMap类常用方法与HashMap类常用方法相同,此处不再演示
遍历集合¶
LinkedHashMap类遍历集合与HashMap类遍历集合的方式相同,此处不再演示
Map接口自定义类型去重的方式¶
以下面的自定义类为例:
| Java | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | |
以下面的测试为例:
| Java | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
前面在Set部分提到HashSet的去重方式:
- 先计算元素的哈希值(重写
hashCode方法),再比较内容(重写equals方法) - 先比较哈希值,如果哈希值不一样,存入集合中
- 如果哈希值一样,再比较内容
- 如果哈希值一样,内容不一样,直接存入集合
- 如果哈希值一样,内容也一样,去重复内容,留一个存入集合
在Map接口中也是同样的方式去重,所以对于自定义类型来说,一样需要重写equals和hashCode方法
如果Person类没有重写hashCode和equals方法,此时Person对象比较方式是按照地址比较,所以对于第三个元素和第四个元素来说是两个元素,此时输出结果就会是下面的情况:
| Java | |
|---|---|
1 2 3 4 | |
而重写了hashCode和equals方法后,就可以避免上面的问题:
| Java | |
|---|---|
1 2 3 | |
Set接口和Map接口无索引操作原因分析¶
哈希表中虽然有数组,但是Set和Map却没有索引,因为存数据的时候有可能在同一个索引下形成链表,如果1索引上有一条链表,根据Set和Map的遍历方式:「依次遍历每一条链表」,那么要是按照索引1获取,此时就会遇到多个元素,无法确切知道哪一个元素是需要的,所以就取消了按照索引操作的机制

HashMap无序但LinkedHashMap有序原因分析¶
HashMap底层的哈希表是数组+单向链表+红黑树,因为单向链表只有一个节点引用执行下一个节点,此时只能保证当前链表上的节点元素可能与插入顺序相同,但是如果使用双向链表就可以解决这个问题,过程如下:
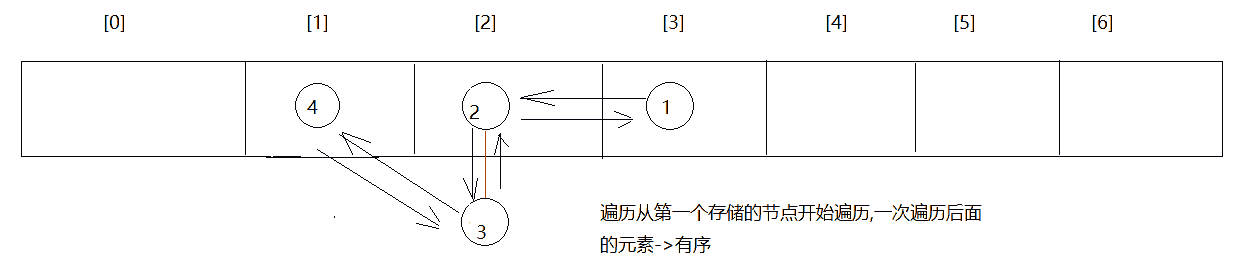
哈希表结构存储过程分析¶
HashMap底层的数据结构是哈希表,但是不同的JDK版本,实现哈希表的方式有所不同:
- JDK7时的哈希表:数组+单链表
- JDK8及之后的哈希表:数组+链表+红黑树
以JDK8及之后的版本为例,存储过程如下:
- 先计算哈希值,此处哈希值会经过两部分计算:1. 对象内部的
hashCode方法计算一次 2.HashMap底层再计算一次 - 如果哈希值不一样或者哈希值一样但内容不一样(哈希冲突),直接存入
HashMap - 如果哈希值一样且内容也一样,则发生
value覆盖现象
在Java中,HashMap在实例化对象时,如果不指定大小,则默认会开辟一个长度为16的数组。但是该数组与ArrayList一样,只有在第一次插入数据时才会开辟容量
而哈希表扩容需要判断加载因子loadfactor,默认负载因子loadfactor大小为0.75,如果插入过程中加载因子loadfactor超过了0.75,就会发生扩容
存储数据的过程中,如果出现哈希值一样,内容不一样的情况,就会在数组同一个索引位置形成一个链表,依次链接新节点和旧节点。如果链表的长度超过了8个节点并且数组的长度大于等于64,此时链表就会转换为红黑树,同样,如果后续删除节点导致元素个数小于等于6,红黑树就会降为链表
哈希表结构源码分析¶
查看源码时可能会使用到的常量:
| Java | |
|---|---|
1 2 3 4 5 6 | |
查看源码时会看到的底层节点结构:
| Java | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
使用无参构造创建HashMap对象¶
测试代码:
| Java | |
|---|---|
1 | |
对应源码:
| Java | |
|---|---|
1 2 3 | |
第一次插入元素¶
测试代码:
| Java | |
|---|---|
1 2 | |
对应源码:
| Java | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 | |
Note
threshold代表扩容边界,是HashMap中的成员变量,由容量和负载因子相乘计算得到
在上面的代码中,插入数据调用put方法,底层会调用putVal方法,进入putVal后,首先会判断当前表是否为空,而此时因为是第一次插入元素,元素还没有进入表中,当前表为空,所以会走第一个if语句,进入内部执行n = (tab = resize()).length;会执行resize方法为当前的tab扩容
进入resize方法中,当前的成员table即为HashMap底层的哈希表,因为不存在元素,所以为空,从而oldTab也为空,执行后面的代码后oldCap和oldThr均为0,直接进入else语句中,将newCap置为16,同时将newThr赋值为12,执行完毕后,将成员threshold更新为newThr的值,将新容量16作为数组长度创建一个新的数组newTab,将newTab给成员变量table返回给调用处继续执行
Note
此处需要注意,对于Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];来说,因为Java不支持创建泛型数组,所以先创建原始类型数组再通过强制转换将其转换为泛型数组
回到调用处n = (tab = resize()).length;,此时tab即为成员变量table的值,获取其长度即为16。接着执行第二个if语句,此处的i = (n - 1) & hash用于计算哈希表的映射位置,即数组索引,进入if语句,创建节点并插入到指定索引位置,改变size并比较是否超过threshold,此处未超过不用扩容,改变并发修改控制因子,返回被覆盖的null
使用有参构造创建HashMap对象¶
测试代码:
| Java | |
|---|---|
1 | |
对应源码:
| Java | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
当执行有一个参数的构造时,底层调用内部的有两个参数的构造,第一个参数即为初始容量大小,第二个参数传递默认的加载因子
在有两个参数的构造中,首先判断初始容量initialCapacity是否小于0,如果小于则抛出异常,再判断初始容量initialCapacity是否大于最大值,如果大于则修正为最大值。
在执行完所有判断后,将加载因子赋值给成员变量loadfactor,再根据初始容量计算扩容前最大的容量
哈希值相同时比较源码¶
| Java | |
|---|---|
1 2 3 | |
首先比较哈希值,如果哈希值相同,则比较key对应的value,为了防止出现key为空导致的空指针问题,先判断key不为空,再比较key
上面过程即「先比较哈希值(重写hashCode方法),相同再比较内容(重写equals方法)」,所以插入元素的过程如下
- 先比较哈希值,如果哈希值不一样,存入集合中
- 如果哈希值一样,再比较内容
- 如果哈希值一样,内容不一样,直接存入集合
- 如果哈希值一样,内容也一样,去重复内容,留一个存入集合
所以前面之所以重写了equals方法的同时还需要重写hashCode就是为了尽可能保证内容比较和去重的可靠性
总结:对于自定义类型来说,如果不需要打印对象的地址而是打印对象的内容就重写toString方法,而需要比较对象是否相同除了内容比较还需要进行hashCode比较,所以需要重写equals和hashCode方法
HashTable与Vector¶
HashTable类是Map接口的实现类,其特点如下:
key唯一,value可重复- 插入顺序与存储顺序不一定相同
- 没有索引的方式操作元素
- 线程安全
- 不能存储
null值
底层数据结构:哈希表
Vector类是Collection接口的实现类,其特点如下:
- 元素插入顺序与存储顺序相同
- 有索引的方式操作元素
- 元素可以重复
- 线程安全
底层数据结构:数组
因为HashTable和Vector现在已经不经常使用了,所以使用及特点自行了解即可
Properties类¶
Properties类介绍¶
Properties类是HashTable类的子类,其特点如下:
key唯一,value可重复- 插入顺序与存储顺序不一定相同
- 没有索引的方式操作元素
- 线程安全
- 不能存储
null值 Properties类不是泛型类,默认元素是String类型
底层数据结构:哈希表
Properties类特有方法¶
常用方法与HashMap等类似,此处主要考虑特有方法:
Object setProperty(String key, String value):存键值对String getProperty(String key):根据key获取对应的valueSet<String> stringPropertyNames():将所有key对应的value存储到Set中,类似于HashMap中的KeySet方法void load(InputStream inStream):将流中的数据加载到Properties类中(具体见IO流部分)
基本使用如下:
| Java | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
Map练习案例¶
案例1:统计字符串每一个字符出现的次数¶
统计字符串:abcdsaasdhubsdiwb中每一个字符出现的次数
思路:
遍历字符串依次插入HashMap<String, Integer>(或者LinkedHashMap<String, Integer>)中,这个过程中会出现两种情况:
- 字符不存在与
HashMap中,属于第一次插入,将计数器记为1 - 字符存在于
HashMap中,代表非第一次插入,将计数器加1重新插入到HashMap中
代码实例:
| Java | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
案例2:斗地主案例HashMap版本¶
思路:
使用HashMap存储每一张牌(包括值和样式),key存储牌的序号(从0开始),value存储牌面,使用前面同样的方式组合牌并存入HashMap中,存储过程中每存一张牌,key位置的数值加1。为了保证可以打乱牌,需要将牌面对应的序号存入一个单列容器,再调用shuffle方法。打乱后的牌通过序号从HashMap中取出,此时遍历HashMap通过key获取value即可
其中,有些一小部分可以适当修改,例如每一个玩家的牌面按照序号排序,查看玩家牌可以通过调用一个函数完成相应的行为等
Note
此处当key是有序数值,会出现插入顺序与存储数据相同
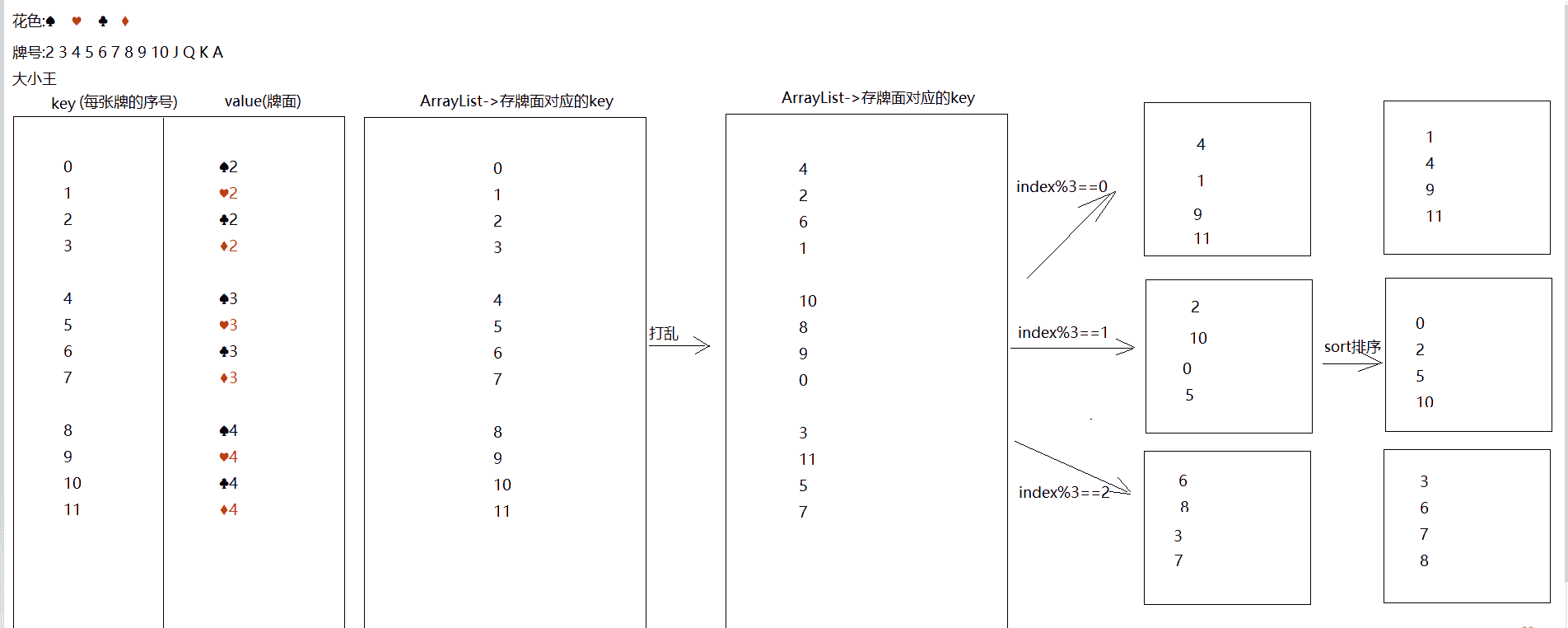
示例代码:
| Java | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 | |